
Causal factors discovering from Chinese construction accident cases
Zi-jian Ni
a,∗
, Wei Liu
a
a
Faculty of Economics and Management, Dalian University of Technology
2 Ling Gong Rd., Dalian 116024, Liaoning, P. R. China
Abstract
In China, construction accidents have killed more people than any other industry since 2012.
The factors which led to the accident have complex interaction. Real data about accidents is
the key to reveal the mechanism among these factors. But the data from the questionnaire
and interview has inherent defects. Many behaviors that impact safety are illegal. In China,
most of the cases are from accident investigation reports. Finding out the cause of the
accident and liability affirmation are the core of incident investigation reports. So the truth
of some answers from the respondents is doubtful. With a series of NLP technologies, in
this paper, causal factors of construction accidents are extracted and organized from Chinese
incident case texts. Finally, three kinds of neglected causal factors are discovered after data
analysis.
Keywords: Roles mismatch, Natural Language Processing (NLP), Accident cases,
Accident causes
1. Introduction
China, as the largest construction market in the world, its value of construction output
was about 24.8 trillion Yuan in 2019. Concerning safety in the construction industry, it
is still challenging today [1]. The death toll reached 1152 in 2003 and then fell for 11
consecutive years. With the holistic improvement of the occupational health and safety
management system of the country, however, accidents in the construction industry have
killed more people than in coal mines since 2012. In 2019, construction deaths on the job
were 904, which ranked the first in all types of industrial accidents. Many studies hold that
construction is one of the most dangerous industries due to the complicated and multicausal
factor of accidents on project sites [2, 3].
In [4], accident causation theories were divided into four generations: accident proneness
theories, domino theories, injury epidemiology models, and system theories. In the last
generation, occupational safety is impacted by factors in different levels that have complex
interactions. Further, two kinds of elements are analyzed in the construction accident system
∗
Corresponding author
Preprint submitted to May 5, 2021
arXiv:2105.01227v1 [cs.AI] 4 May 2021
model. One is the factors influencing safety performance, which is called the risk factor. And
the other is the causal factor. As the name implies, they resulted in the accident.
Generally, the system model about risk factors is based on the empirical method. The
whole research begins with statements or hypotheses. After data collection from the ques-
tionnaire and interview, whether a hypothesis is supported or not depends on the appropriate
statistical formula. All kinds of specific aspects of construction safety have been discussed
in this methodology. Thirteen main risk factors from 55 papers are summarized in a useful
review [5]. In construction accident analysis, there is an essential weakness of this kind
of empirical research. Many behaviors that impact safety is illegal. So the truth of some
answers from the respondents in the questionnaire and interview are doubtful.
Moreover, the unsafety does not equal to the accident. Revealing the causality of ac-
cidents is essential to distinguish between factors that require some action or not [6]. The
research shows that causes of accidents vary substantially between industries [7]. Most causal
models of construction accident [2, 8, 9, 10] originated from systematic and holistic thinking
about accidents. But not all of them have been validated by sufficient real accident data.
In work [10], for example, only a small sample of fatal accidents (26 in total 211 accidents
cases) was used to understand underlying causes. Another example is causal factors were
divided into the proximal and distal in the [2]. But because of the limitations of the acci-
dent data available, only the proximal factors are validated [2]. The ConAC (Construction
Accident Causality) framework [8] was verified [6, 11] and applied [12] a couple of times.
But at the same time, analyzing data is the cost. For extraction data from 84000 words,
this study engaged four analysts [11]. The consistency of criteria for extracting information
is still problematic, even if you can hire more skilled professionals. As a result, for analyzing
construction accidents, real data is the key.
Not only in the field of construction, but it is also hard to collect data of accidents in other
industries. The reason is that it is impossible to conduct reproducible incident experiments
like other disciplines. Past accident analysis and learning (PAL) is always one of two pillars
on which the edifice of occupational safety research [13]. For PAL, accident cases are one of
the most important sources [14]. In China, most of the cases are from accident investigation
reports [15]. Finding out the cause of the accident and liability affirmation are the core of
incident investigation reports. [16]. Including illegal acts, in other words, causal factors of
every accident can be found in these documents. NLP (Natural Language Processing) can
assist people in improving the performance of analyzing the unstructured text. In this paper,
causal factors of construction accidents will be extracted from the free text in Chinese with
Automatic Keyphrase Extraction (AKE) [17]. AKE includes a series of NLP technologies
and will be discussed in section 3. Furthermore, not only for incidents of construction, we
believe that our framework for the extraction can be used in other industry accident case
text in Chinese.
For evaluating the necessity and sufficiency of causal factors in data sets, all valid accident
data in a short-term was input into various algorithms to get the correlation. Because our
Chinese cases are typical incidents for an extended period (more than 25 years), the holistic
causal model can not be proposed in this paper. But due to more accurate information
being extracted and summarized, some neglected causal factors will be revealed. In the
2

meanwhile, empirical studies may be inspired by these real accident data also. Finally, the
organized data will be shared online for further studies
1
.
The rest of this paper is structured as follows: The data source and the case text structure
will be introduced in section 2. A framework for extraction causal factors from texts will be
proposed in section 3. In section 4, the role mismatch and the other two neglected factors
will be discussed.
2. Accident causes in Chinese accident cases
Case title
Project profile...(optional)
Client
Contractor
Details of the accident and Emergency response
Causes of the accident
Direct cause
Indirect cause
Accident severity
Liabilities
Accident prevention and improvements...(optional)
Figure 1: The structure of Chinese construction accident cases.
In our study, 267 typical construction accident cases are all from esafety.cn, which is
the information platform of the Ministry of Emergency Management of China. The text
structure of a Chinese accident case is listed in Fig. 1. Some projects are small, and none
of the stakeholders are corporations. But the loss is severe. So chapters about the project
profile and accident prevention and improvements are sometimes omitted. However, the
accident causes are the core of the document.
Moreover, there are causes-and-effects relationships between two kinds of causes in the
cases. Direct causes have two main factors, which are unsafe behaviors of people and hazard
status of matters. Furthermore, the matter includes equipment, material, and surroundings.
The indirect cause can lead to immediate causes and thus increase the risk of projects, which
is similar to distal causal in [2]. Details of the indirect cause will be discussed in section 4.1.
As discussed above, most of the Chinese cases are from accident investigation reports.
And the legal base of investigation reports is Regulation for the Investigation of Casualty
Accidents of China (RICAC) [18]. Professor Sui is one of the counselors of RICAC, who
proposed an accident model called the cross-track model [19]. This model illustrates the
relation between direct and indirect causes. In Fig. 2, the unsafe behaviors and hazard
statuses of matters are understood as a consequence of management failures. Moreover, the
accident is not an inevitable outcome. But as the project goes on, loss expectation will
increase until an accident happens.
1
https://github.com/liuwei-965/Digital-management-of-Chinese-accident-cases
3

Figure 2: Cross track model: causes-and-effects relationships between direct causes and indirect causes.
3. Extract causal factors for each accident
Figure 3: An example for keyphrases, which are indirect causes of an accident. Texts with underline are the
keyphrases for the cause. And the grey one is high-frequency word.
Although causal factors are rich in the two specific sub-sections of case texts, not every
word is about the cause. In Fig. 3, there is an example from one real case text. The parts
with underlines describe the causes of the accident. Rather than one single word, a sequence
of words makes up this description, which is called the phrase [20]. Moreover, an observation
in Fig. 3 is that only some phrases are valuable to analyze causal factors. In this paper,
these phrases are called keyphrases. Finally, more than one keyphrases can express the full
meaning of accident causes. This kind of keyphrases set is called the fact.
Each case text contains more than one fact about the accident. Based on a series of NLP
techniques, in this section, a framework will be proposed to extract these facts. Due to the
complexity and ambiguity of natural language, there are many ways of expressing the same
semantic [21]. So it is almost impossible to find every fact from the free text. Our study,
due to the above, is based on one assumption that people and organizations repeat the same
mistakes always. As a result, if our framework can extract frequent causes automatically,
the manual workload for the rests will be very reduced.
4

3.1. Framework for extraction
Automatic Keyphrase Extraction (AKE) is a task of natural language processing (NLP),
which may be divided into two kinds [17]: supervised and unsupervised. Although promising
results were delivered from current supervised AKE approaches, both the data labeling and
manual sorting facts are time-consuming. Without training data, unsupervised AKE is a
recent trend aimed at discovering the underlying structure of a document [22]. The graph-
based model is a typical method of unsupervised AKE [23, 24], in which the whole text
is switch to the network, words as nodes. Based on different standards, each node gets a
weight to evaluate its importance. Then rank nodes by their weight, and select nodes of top
rank as keyphrases at last. However, based on this graph-based model, it can not guarantee
a phrase representing the text theme is a top-ranking term if it does not frequently occur in
the text. In the text of Fig. 3, the occurrences of some phrases are much higher than anyone
of keyphrases. For example, Songyuan appears 3 times, Property Management appears 4
time and Property Management Co., LTD. is 3.
Figure 4: Keyphrase extraction process stages.
Although the weighted network’s topology can not be used as an extraction basis in our
data, the following two features are still valuable.
1. The core of causal factors is usually verb phrases in Chinese.
2. If people repeat the same mistake, which is the assumption discussed in section 3, one
causal factor in one case will appear in others.
Based on the above features about the case text, the whole workflow is depicted in Fig. 4.
In this process, the core parts are the candidate identification (step 2) and feature engineering
(step 3). In stage 2, candidate phrases sets will be identified through dependency syntax
analysis (DSA) and heuristic rules. The core meaning of every sentence will be extracted
in this step. If multiple candidate phrase sets have a similar semantic, in the next step,
keyphrases sets (facts) will easily be brought together with the semantic clustering.
3.2. Case text pre-processing
In the preprocessing stage, text data will be formatted into a machine-readable format
to decrease their complexity. In Chinese, a part of a sentence that can provide additional
information for the sentence is called the sense group [25]. And sense groups of a sentence
5
are divided into commas, semicolons, and full stops. We believe that a sense group can
retain the whole meaning of a fact. To this end, after noisy symbols are removed, sentences
will be segmented by the three kinds of punctuation. In our studies, these segments are
called candidate clauses.
3.3. Identification of candidate phrases sets
In this stage, candidate clauses will be transformed into candidate phrase sets.
For detecting all candidate phrases sets, three main methods were used by previous
studies: N-Gram based [26, 27], Part-Of-Speech (POS) sequence based [28] and both [29].
All methods above fall into the lexical analysis. According to the characters of our data,
a novel method based on syntactic analysis will be proposed in this paper. Dependency
parsing is quite a vital grammar analysis tool [30]. In the dependency grammar, rather than
the constituent and structure of solo phases, binary grammatical relations between words
are directly described.
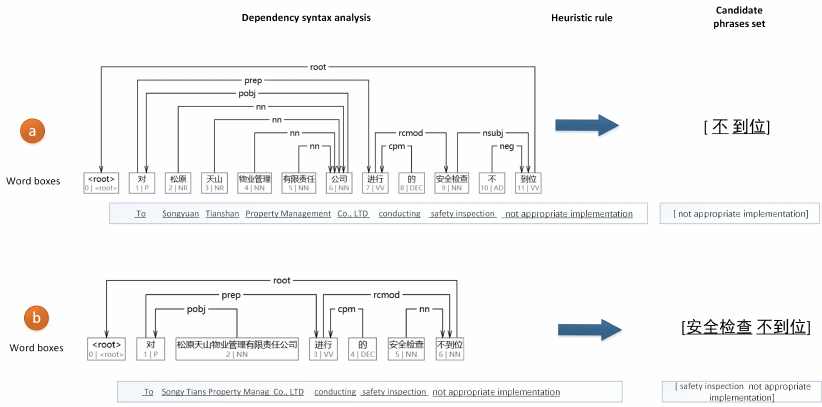
Figure 5: Two examples of candidate identification. Candidate clauses in the two examples are the same.
Because of different segmentations, results are very different.
In Fig. 5, there are two examples of the sentence dependency syntax analysis (DSA).
A Chinese sentence is cut into words (or phrases). Each one, in Fig. 5, is in a top part
of a word box. And the bottom part of this box is the sequence number and part of the
speech of it. On the top of the word boxes, the directed edge is from the headword to its
dependent. And the labels are all from a fixed library of syntax relations [31]. There must
be a root node in the dependency structure, which is the head of others. Note that if the
sequence number of the headword is less than the dependent’s, the arc is called reverse
syntax relation.
With heuristic rules, the DSA results of candidate clauses will be extracted to get can-
didate phrase sets. Generally, the root of a sentence is a verb phrase, which is the core of
6

causal factors. As a result, the start point of extraction of rules is the root phrase. Further,
the other two rules will help to find the rest candidate phrases if they exist.
1. Taking the root as the start, its nearest dependent will be extracted.
2. The headword and dependent of some certain reverse syntax relation will be extracted,
which is the nearest to the root. These reverse syntax relations include direct object
(dobj ), object of preposition (pobj ), adjectival complement (acomp).
In the sub-figure b of Fig. 5, the last phrase is the root of the whole sentence, so there is
no reverse syntax relation in it. And following rule 1, namely the nearest dependent of the
root, safety inspection can be extracted. By rules, the candidate phrases set of this clause
is ‘safety inspection not appropriate implementation’.
Moreover, an important observation in Fig. 5 is that although the candidate clauses and
the rules are the same, the results are different. The reason is different ways of sentence
segmentation. With classical methods, in sub-figure a of Fig. 5, the clause is divided into
words. And the complete fact can not be found by rules. Rather than words, in the sub-
figure b, the same sentence is cut into phrases. The phrase, in Chinese, is a group of words
or a single word, which is a single unit in the grammar of a sentence. In the example above,
a group of words is combined to Songy Tians Property Manag Co., LTD which is a noun
phrase. And the phrase in the last box is an adverbial phrase.
A few kinds of noun phrases, such as organizations and locations, can be found by
one NLP technology called named-entity recognition (NER) [32]. Other kinds of phrases,
including some noun phrases, need a novel method. Phrases extraction, essentially, is the
assignment to identify combinations of words that show some idiosyncrasy in some certain
corpus [33]. In this paper, this idiosyncrasy will be evaluated by a mixed index [34]. The
equation is as follows:
Score(b) = P MI(w
i
, w
j
) + min(H
L
C(b), H
R
C(b)) (1)
In the phase extraction, two sequential words in the text are called the bigram. Let w
i
, w
j
be a bigram in the corpus, which is denoted by b. The score of bigram b, in Equ. 1, is
composed of two parts, which will be used to evaluate whether b can be a phrase. Specif-
ically, P MI(w
i
, w
j
) is the inner connection index and min(H
L
C(b), H
R
C(b)) is the outer
independence index.
Pointwise mutual information (PMI) is one of the standard connection measures in the
phrase extraction, which was introduced into NLP by Church and Hanks [35].
P MI(w
i
, w
j
) = log(
P (w
i
, w
j
)
P (w
i
) × P (w
j
)
) (2)
P (w
i
, w
j
) is the probability of the bigram w
i
, w
j
, which can be gotten by the maximum like-
lihood estimation. P (w
i
, w
j
) = C(w
i
, w
j
)/N, where C(w
i
, w
j
) is the number of occurrences
of the bigram and N is the number of words in the corpus. By the same way, P (w
i
) and
P (w
j
) can be estimated also.
7

PMI as an inner connection index can not be used to evaluate whether the bigram is a
complete phase. P MI(Songyuan, T ianshan)
2
, for example, may have a high PMI value.
But ‘Songyuan Tianshan Property Manag Co., LTD’ is a whole noun phrase. In other words,
by the outer index, a bigram can be independent of contextual words.
If contextual words of a bigram are always in change, we believe that it may well be
a complete semantic unit [36] (phrase). Information entropy can be used to calculate the
chaos and unpredictability of a random variable. Let LC(b) = {w
1
, ..., w
n
} be left context
words set of the bigram. Thus the left entropy of bigram can be defined as:
H
L
C(b) =
X
w
i
∈LC(b)
P (w
i
)log
2
P (w
i
) (3)
By MLE, P (w
i
) = C(w
i
)/N, where C(w
i
) is the number of occurrences of word w
i
appearing
to the left of b, and N is total number of occurrences that all adjacent words appear to the
left of b. In the same way, the right entropy of b can also be got.
Finally, based on these scores, the bigrams set will be ranked. And top-ranked ones may
be returned as phrases. Note that the phrase extraction can be operated repeatedly until as
many whole semantic units as a possible return.
3.4. Feature engineering
In this step, accident facts will be identified. In AKE, characters that can distinguish
keyphrases from others in the candidate set are called features. TF-IDF (Term frequency
- Inverse document frequency) is the most popular feature [37, 38]. TF-IDF can select
candidate phrase sets that are frequent in a given document but infrequent in the whole
corpus. As shown in Fig. 3, facts can not be identified because of less frequency. Assuming
that people always repeat the same mistakes, a novel feature will help to pick keyphrases in
our studies.
Repeating the same mistakes means the facts with similar semantics appear in many
different candidate phrase sets. As a result, the cluster based on the semantic similarity can
characterize keyphrases sets from others. By counting the minimum number of operations
required to switch one string to the other, edit distance is a method to evaluate the semantic
similarity [39] between two candidate phrases sets. In our work, types of operation contain
the insertion, removal, or substitution of a character in the string. This kind of distance is
2
Songyuan is the name of a city. Tianshan is a mountain
8
called Levenshtein distance [40] which is defined as the following.
sem(a, b) = lev(a, b) =
|a| if|b| = 0
|b| if |a| = 0
lev(tail(a), tail(b)) if a[0] = b[0]
1 + min
lev(tail(a), b)
lev(a, tail(b))
lev(tail(a), tail(b))
otherwise
(4)
lev(a, b) is the Levenshtein distance of the two strings a, b and |a|, |b| is the length of
them. The tail of string a (tail(a)) is the string of all but the first character of a, and
a[n] is the nth character of the string a, starting with character 0. For the two strings
a, b (|a| > 0, |b| > 0), if they’re exactly the same, lev(a, b) = 1. Further, the larger the
difference between a, b, the higher the Levenshtein distance. As a result, lev(a, b) can be
used to evaluate semantic similarity. Let T
D
be the candidate phrases. Levenshtein distance
is used to get the pairwise similarities between each pair of phases in T
D
. And the result is
a similar matrix of size |T
D
| × |T
D
|, which is denoted by SC.
Then, SC will be clustered. There are many kinds of algorithms to cluster SC efficiently,
but not all can analyze the distance matrix. DBSCAN [41] is a robust algorithm that does
not need to specify the number of clusters. DBSCAN requires two parameters. One is
the radius of a neighborhood with respect to some point denoted by ε. The other is the
minimum number of points (minP ts) required to form a dense region. A point is a core
point if at least minP ts points (including the core point) are within distance ε of it. With
the core point, DBSCAN will cluster all points (core or non-core) that are reachable from
it.
Every parameter will influence the result of an algorithm, which is the key for every
mining task. To DBSCAN, ε and minP ts as parameters are needed to specified by the user.
• minP ts is then the desired minimum cluster size. Because people always repeat the
same mistakes, minP ts can be set a little higher. Generally, higher values are better
for data sets with noise sets and will yield more significant clusters. Here noise sets
mean the content of the phrase set is nothing about the cause of the accident. In the
clustering process of our study, minP ts is always 5.
• It is hard to estimate ε because there are many ways to express the same semantic in
the free text. But it is much easier to get a minimum value of ε than its maximum
value. If two candidate phrases sets are the same, which is very common in SC, the
Levenshtein distance between them is 1. So the lower bound of ε is 1. If ε is chosen
much too small, a large part of the data will not be clustered. The example is in
Fig. 6. Two candidate phrase sets are all about warning signs being ignored when the
Levenshtein distance between them is not small, which is 1.9. Namely, if ε < 1.9, it is
9

quite possible that they are considered as noise set by DBSCAN. And for a too high
value of ε, clusters will merge, and most nodes will be in the same cluster.
Figure 6: The two sentences have similar semantics, which can be classified into one causal factor. However,
the Levenshtein distance between them is not small, which is 1.9.
In our work, a succinct multi-density clustering will be implemented in our candidate
phrases sets. The algorithm is listed as the following:
1. To candidate phrases set SC, ε is determined by comparison.
2. With ε, some clusters will be mined from SC.
3. If any two phrases in one cluster satisfy lev(a, b) = Max(|a|, |b|), the algorithm will
stop. All clusters mined by the algorithm are the result.
4. If not, delete candidate phrases set belonging to any clusters from SC to form a new
SC. And repeat step 1.
The whole process is depicted in Fig. 7.
Figure 7: The algorithm flow of multi-density. ε
1
< ε
2
< ... < ε
n
. SC will be clustered by ε
1
. The the
phrases in any clusters will be removed from the SC. And the rests will be be clustered by ε
2
. Repeat the
two steps above until the condition is met.
The subgraph named Round1 in Fig 8 depicts the relationship between the ε and the
number of clusters. The whole SC is clustered by different ε whose value is from 1.1 to 1.5.
The peak number of clusters appears in ε = 1.32, which is chosen as the value of the radius
of a neighborhood in round 1. The same pattern about the number of clusters appears
in the rest of the data until the stopping rule is satisfied. Note that the terminal rule is
lev(a, b) = Max(|a|, |b|), which means there is not one same character in the string a and
b. In our data set, round 6 is the last clustering and ε
6
= 3 The radius from ε
1
to ε
5
are
depicted in Fig. 8.
10

Figure 8: The value of ε used in the multi-density clustering.
3.5. Summary for extracting causal factors
267 accident case texts are input into our extracting framework, in which accidents
happened from 1998 to 2018. And 5598 candidate clauses format from these text data. Of
course, 5598 candidate phrase sets are ready for clustering analysis by DSA and heuristic
rules extracting. After six rounds of multi-density DBSCAN, 355 clusters are the final result,
and 664 phrases sets are not contained by any clusters. In 664 sets, only 3 are not noise
sets.
Note that only 40 clusters (in 355) are noise set also. After removing duplications, 1669
phrase sets about accident causations are the keyphrase sets. Then each case text will
retrieval these key sets to get the recall. More specifically, if a clause in the text includes
a whole essential phrase set, the causal factor is identified. The recall of our framework is
87%.
4. New causal factors discovery
As discussed above, the scale of risk factors in the construction are much larger than the
causal factors. An excellent review [5] investigated 55 previous papers, and 95 sub-factors
are summarized into 13 main factors. In contrast to risk factors, ConAC, which is a causal
model, only considers Four main factors and 19 sub-factors [11]. As a result, for revealing
new causal factors, we try to classify 1669 facts into 95 sub-factors until someone can not
be laid down. If some of these neglected facts have common characteristics, we can say one
novel causal factor is discovered.
4.1. Role mismatch
The first one, which caught our attention, is a fact which is ‘fake many times to defraud
franchise’. Not only is this fact not classified into any 13 primary factors, but it makes
11
me wonder what has happened in that accident. Then we went back to read the case text
and found that it was a complicated accident
3
. In brief, to save money, a big project is
masqueraded as a small one by lying to the government first. Then the client finish jobs
of the contractor, supervision, and engineering designer. Because of the improper plan,
insufficient strength of columns led to concrete formwork collapsing. Seven people died, and
over ten were injured in this accident. It is impossible for respondents in the questionnaire
or interview to admit such a severe crime.
Stakeholders are the organizations who are actively involved with the project’s work
or have something to either gain or loss due to the project [42]. Much more than other
industries, there are five kinds of directly involved organizations in China, including the
government, client, project supervision, contractor, and others (Land survey, design, equip-
ment leases, etc.). One stakeholder unfulfilling his responsibility to result in an accident has
drawn attention from previous studies [43, 44]. But few people note that one stakeholder
did something beyond their scope of duties and cause accidents. In this paper, this is called
role mismatch. One example is the client in the last paragraph.
From 267 case texts, six kinds of role mismatch are summarized, which is listed in Tab.
1. Except for supervisors, the other five kinds of stakeholders are included. The second
column of Tab. 1 is the occurrence number of this sub-factor in total 267 cases. If two
factors appear in the same accident frequently, there may be a strong correlation between
them. Before discussing the relations between role mismatch and other causal factors, a
classification of causal factors will be proposed first.
The case data character is each accident fact has a stakeholder who has to be held
accountable. As a result, six main factors correspond to six different kinds of stakeholders
in the construction industry in our classification. Each stakeholder’s responsibilities in the
construction safety are defined in two laws of China [45, 46], which are Construction Law
and Regulations on construction engineering quality management, respectively. So the sub-
factors are all from the two laws. Rather than open interpretation [12], the definition of
these factors in the law is more strict. The main factors and their sub-factors are listed in
Tab. 3 of Appendix A. Note that the number in the bracket is the code of this sub-factor.
And these codes correspond to the number in the last column in Tab. 1.
If two factors appear in the same accident frequently, there may be a strong correlation
between them. Moreover, the causal diagrams [47] of the construction accident can be
deduced from these correlations. With role mismatch, factors that appear in the same
accident are listed in the last column in the Tab. 1. And the number of co-occurrence is in
the bracket behind the factor code. Based on causal diagrams [47], the mechanism of role
mismatch will be discussed in our future work. Here we only come up with some preliminary
observations. Except for government appointing sub-contractor, reducing costs and saving
time may be the common purpose of the rest five sub-factors.
12

Table 1: Relations between role mismatch and other causal factors
Role mismatch Occurrence
number
Other factors in the same accident
Client: making construction
plan
1 6-2(1) 2-7(1) 2-12(1) 2-3(1)
Government: appoint sub-
contractor
1 2-12(1) 2-7(1) 3-1(1) 2-3(1)
2-7(33) 2-12(12) 3-4(5) 4-1(16)
2-13(26) 1-3(11) 5-2(3) 2-11(6)
Contractor: construction 41 2-3(23) 3-1(11) 4-3(2) 3-5(1)
without competency 1-1(23) 2-4(11) 6-1(2) 2-5(15)
5-1(22) 2-8(9) 2-9(2) 6-2(6)
1-2(18) 2-1(9) 4-4(2) 2-10(13)
3-2(16) 2-6(8) 4-2(1) 2-2(5)
2-13(5) 1-1(3) 1-2(2) 3-2(3)
2-7(5) 2-10(3) 3-1(2) 4-3(1)
Contractor: 5 2-3(5) 2-5(2) 2-6(1) 4-1(2)
illegal transfer 5-1(4) 2-11(2) 1-3(1) 2-12(2)
2-8(3) 5-2(2) 2-2(1) 2-4(1)
2-1(3)
1-2(48) 2-6(22) 4-3(7) 2-12(27)
2-3(43) 1-3(19) 3-4(6) 2-1(12)
2-7(40) 2-5(19) 2-11(5) 4-2(2)
Worker: labour 57 5-1(37) 2-10(18) 6-2(5) 2-4(25)
without competency 4-1(35) 2-13(17) 6-1(5) 3-1(12)
1-1(31) 3-2(16) 5-2(4) 4-4(2)
2-8(30) 2-2(14) 2-9(3)
2-7(4) 1-2(3) 6-1(1) 4-4(1)
Designer: 4 5-1(4) 1-1(3) 2-2(1) 2-10(1)
without competency 6-2(4) 3-2(3) 2-12(1) 3-4(1)
2-13(4) 2-4(2) 2-1(1) 3-5(1)
2-3(4) 3-1(2) 4-1(1)
13

Table 2: The other two neglected causal factors
Main factor Sub-factors Accident case title
Supplier: Failure to fully perform the
contract
2003-9-20 Lift cage falling
No engineer contract 1996-3-14 The earth collapsed
Engineer contract
management
No labor contract 2003-5-15 The car crane collided with the high voltage line
In Inappropriate contract management 2002-3-15 Crane boom overturned
2003-9-12 Pipe network trench collapse
2002-11-6 Falling
Delayed response 2001-6-20 The outer cornice collapsed
2003-7-24 The building collapsed
No contingency plan 2002-5-12 Explosion
Response 2003-11-20 Construction collapse
for the accident Contingency plan has not been imple-
mented
2014-9-1 Poisoning in a sewage pumping station project
Inappropriate rescue 2003-3-29 Poisoning in a sewerage project
2012-12-23 Carbon monoxide poisoning
4.2. More than one neglected factor
From case text data, the other two main factors are relatively little studied in construction
accidents. One is engineering contract management, and the other is the response to the
accident. We believe that the reason for neglecting is also data problems. It is hard to collect
enough samples because the people who have participated in rescue or contract management
are very few.
With case texts, other scholars may be inspired by the two factors and their sub-factors.
In Tab. 2, the sub-factors are listed in the second column. Note that all of these sub-factors
are summarized from the real accident cases, and the date and title of them are in the last
column. And our share data in Github has these case texts.
5. Conclusion
The accident data is valuable. After the whole process of past accidents is revealed, the
future losses can be reduced. Very few people have ever had an accident, so the data about
accidents are hard to get. Typical accident cases should be studied carefully because the
cost of life is behind most of these texts. Beyond the limitations of the manual analysis,
based on a series of NLP technologies, a framework to organize data about accident causes
is proposed in this paper. And some neglected causal factors are discovered. Role mismatch
will be further discussed in our future studies.
3
http://www.safehoo.com/item/157796.aspx Last open in 2021.01.15
14
We believe that our framework can also analyze Chinese case texts in other industries.
And the research involving other languages can be inspired by this work. Moreover, society
and economic climate can also affect the occupational incident system [11, 43]. As a result,
other developing countries would benefit from our study also.
Acknowledgements
This work is supported by the National Natural Science Foundation of China Nos. 71501022,
71901047, 71874020 and 71774021.
Appendix A
15

Table 3: Causal factors categorized by stakeholders
Stakeholder Causal factors (ID)
• Unsafe operation (1-1)
1. Worker and Work group • Without competency (1-2)
• Tacit knowledge: ability, experience, knowledge, safety awareness (1-3)
• Responsibilities of contractor is not fulfilled (2-1)
• Construction plan (2-2)
• Safety, quality supervision and control (2-3)
• Rules and regulation (2-4)
• Safety culture and climate (2-5)
2. Contractor • Safeguard procedures, equipment and sign (2-6)
• Inappropriate construction operation (2-7)
• Training and education (2-8)
• Site condition (2-9)
• Command (2-10)
• Verification of competency (2-11)
• Response to the accident (2-12)
• Competency of itself (2-13)
• Safety management (3-1)
• Illegal construction (3-2)
3. Client • Supervising contractors (3-3)
• Project acceptance (3-4)
• Archives management (3-5)
• Supervising contractors (4-1)
• Communication with client (4-2)
4. Supervisor • Competency of itself (4-3)
• Tacit knowledge: ability, experience, knowledge, safety awareness (4-4)
• Guide and supervise (5-1)
5. Government • Inappropriate punishment (Punishment is too light or laws is not strictly enforced)
(5-2)
• Organization, mechanism, system (5-3)
6. Others • Supplier: Material and equipment quality (6-1)
• Designer: Survey and design (6-2)
16
Reference
[1] C. Tam, S. Zeng, Z. Deng, Identifying elements of poor construction safety management in china, Safety
science 42 (7) (2004) 569–586.
[2] A. Suraji, A. R. Duff, S. J. Peckitt, Development of causal model of construction accident causation,
Journal of construction engineering and management 127 (4) (2001) 337–344.
[3] P. H. Mohseni, A. A. Farshad, R. Mirkazemi, R. J. Orak, Assessment of the living and workplace
health and safety conditions of site-resident construction workers in tehran, iran, International journal
of occupational safety and ergonomics 21 (4) (2015) 568–573.
[4] V. V. Khanzode, J. Maiti, P. K. Ray, Occupational injury and accident research: A comprehensive
review, Safety Science 50 (5) (2012) 1355–1367.
[5] A. Mohammadi, M. Tavakolan, Y. Khosravi, Factors influencing safety performance on construction
projects: A review, Safety science 109 (2018) 382–397.
[6] A. Gibb, H. Lingard, M. Behm, T. Cooke, Construction accident causality: learning from different
countries and differing consequences, Construction Management and Economics 32 (5) (2014) 446–459.
[7] A. M. Williamson, A.-M. Feyer, D. R. Cairns, Industry differences in accident causation, Safety Science
24 (1) (1996) 1–12.
[8] S. Hide, S. Atkinson, T. C. Pavitt, R. Haslam, A. G. Gibb, D. E. Gyi, Causal factors in construction
accidents, © Health and Safety Executive, 2003.
[9] P. Mitropoulos, T. S. Abdelhamid, G. A. Howell, Systems model of construction accident causation,
Journal of construction engineering and management 131 (7) (2005) 816–825.
[10] A. Hale, D. Walker, N. Walters, H. Bolt, Developing the understanding of underlying causes of con-
struction fatal accidents, Safety science 50 (10) (2012) 2020–2027.
[11] S. Winge, E. Albrechtsen, B. A. Mostue, Causal factors and connections in construction accidents,
Safety science 112 (2019) 130–141.
[12] M. Behm, A. Schneller, Application of the loughborough construction accident causation model: a
framework for organizational learning, Construction Management and Economics 31 (6) (2013) 580–
595.
[13] B. Abdolhamidzadeh, T. Abbasi, D. Rashtchian, S. A. Abbasi, Domino effect in process-industry
accidents–an inventory of past events and identification of some patterns, Journal of Loss Prevention
in the Process Industries 24 (5) (2011) 575–593.
[14] S. Tauseef, T. Abbasi, S. A. Abbasi, Development of a new chemical process-industry accident database
to assist in past accident analysis, Journal of loss prevention in the process industries 24 (4) (2011)
426–431.
[15] M. of Housing, U.-R. Development, Case analysis of construction safety accidents, China Architecture
Press, 2019.
[16] S. C. of the People’s Republic of China, Regulations on the reporting, investigation and handling of
production safety accidentsconstruction engineering quality management regulations (2007).
URL http://www.gov.cn/zwgk/2007-04/19/content_588577.htm
[17] Z. A. Merrouni, B. Frikh, B. Ouhbi, Automatic keyphrase extraction: An overview of the state of the
art, in: 2016 4th IEEE international colloquium on information science and technology (CiSt), IEEE,
2016, pp. 306–313.
[18] S. A. of China, Regulation for the investigation and analysis of accidents involving casualties of enter-
prise employees.
[19] S. ChengPeng, Casualty accident analysis and prevention principle, Industrial Safety and Environmental
Protection 05 (1982) 1–8.
[20] Z. A. Merrouni, B. Frikh, B. Ouhbi, Automatic keyphrase extraction: a survey and trends, Journal of
Intelligent Information Systems (2019) 1–34.
[21] J. Piskorski, R. Yangarber, Information extraction: Past, present and future, in: Multi-source, multi-
lingual information extraction and summarization, Springer, 2013, pp. 23–49.
[22] H. H. Alrehamy, C. Walker, Semcluster: unsupervised automatic keyphrase extraction using affinity
propagation, in: UK Workshop on Computational Intelligence, Springer, 2017, pp. 222–235.
17
[23] T. Washio, H. Motoda, State of the art of graph-based data mining, Acm Sigkdd Explorations Newslet-
ter 5 (1) (2003) 59–68.
[24] S. S. Sonawane, P. A. Kulkarni, Graph based representation and analysis of text document: A survey
of techniques, International Journal of Computer Applications 96 (19).
[25] D. X. Zhou C., Difficulties and counter measures for machine understanding of chinese: A viewpoint
of the sense-group dynamics, Modern Foreign Languages (Quarterly) 23 (2).
[26] C. Huang, Y. Tian, Z. Zhou, C. X. Ling, T. Huang, Keyphrase extraction using semantic networks
structure analysis, in: Sixth International Conference on Data Mining (ICDM’06), IEEE, 2006, pp.
275–284.
[27] Z. Liu, P. Li, Y. Zheng, M. Sun, Clustering to find exemplar terms for keyphrase extraction, in:
Proceedings of the 2009 conference on empirical methods in natural language processing, 2009, pp.
257–266.
[28] K. Barker, N. Cornacchia, Using noun phrase heads to extract document keyphrases, in: conference of
the canadian society for computational studies of intelligence, Springer, 2000, pp. 40–52.
[29] M. Grineva, M. Grinev, D. Lizorkin, Extracting key terms from noisy and multitheme documents, in:
Proceedings of the 18th international conference on World wide web, 2009, pp. 661–670.
[30] H. Calvo, O. J. Gambino, A. Gelbukh, K. Inui, Dependency syntax analysis using grammar induction
and a lexical categories precedence system, in: International Conference on Intelligent Text Processing
and Computational Linguistics, Springer, 2011, pp. 109–120.
[31] J. Nivre, M.-C. De Marneffe, F. Ginter, Y. Goldberg, J. Hajic, C. D. Manning, R. McDonald, S. Petrov,
S. Pyysalo, N. Silveira, et al., Universal dependencies v1: A multilingual treebank collection, in: Pro-
ceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16),
2016, pp. 1659–1666.
[32] D. Nadeau, S. Sekine, A survey of named entity recognition and classification, Lingvisticae Investiga-
tiones 30 (1) (2007) 3–26.
[33] G. Bouma, Normalized (pointwise) mutual information in collocation extraction, Proceedings of GSCL
(2009) 31–40.
[34] Hankcs, Introduction to nature language processing, People’s posts and telecommunications press, 2019.
[35] K. Church, P. Hanks, Word association norms, mutual information, and lexicography, Computational
linguistics 16 (1) (1990) 22–29.
[36] C.-W. Lee, Y.-L. Wu, L.-C. Yu, Combining mutual information and entropy for unknown word ex-
traction from multilingual code-switching sentences., Journal of Information Science & Engineering
35 (3).
[37] T. D. Nguyen, M.-Y. Kan, Keyphrase extraction in scientific publications, in: International conference
on Asian digital libraries, Springer, 2007, pp. 317–326.
[38] F. Liu, D. Pennell, F. Liu, Y. Liu, Unsupervised approaches for automatic keyword extraction using
meeting transcripts, in: Proceedings of human language technologies: The 2009 annual conference of
the North American chapter of the association for computational linguistics, 2009, pp. 620–628.
[39] M. Baroni, J. Matiasek, H. Trost, Unsupervised discovery of morphologically related words based on
orthographic and semantic similarity, arXiv preprint cs/0205006.
[40] G. Navarro, A guided tour to approximate string matching, ACM Computing Surveys 33 (1) (2001)
31–88. doi:10.1145/375360.375365.
[41] M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al., A density-based algorithm for discovering clusters in
large spatial databases with noise., in: Kdd, Vol. 96, 1996, pp. 226–231.
[42] R. Newcombe, From client to project stakeholders: a stakeholder mapping approach, Construction
management and economics 21 (8) (2003) 841–848.
[43] Q. Chen, R. Jin, Multilevel safety culture and climate survey for assessing new safety program, Journal
of Construction Engineering and Management 139 (7) (2013) 805–817.
[44] A. Pinto, I. L. Nunes, R. A. Ribeiro, Occupational risk assessment in construction industry–overview
and reflection, Safety science 49 (5) (2011) 616–624.
[45] S. C. of the People’s Republic of China, Regulations on construction engineering quality management
18
(1997).
URL http://www.gov.cn/flfg/2005-08/06/content_20998.htm
[46] S. C. of the National People’s Congress, Construction law of people’s republic of china (2019).
URL http://www.npc.gov.cn/npc/c30834/201905/0b21ae7bd82343dead2c5cdb2b65ea4f.shtml
[47] J. Pearl, D. Mackenzie, The book of why: the new science of cause and effect, Basic Books, 2018.
19
